Powered by
Cut down on LLM expenses and optimize quality with a top-notch RAG cache
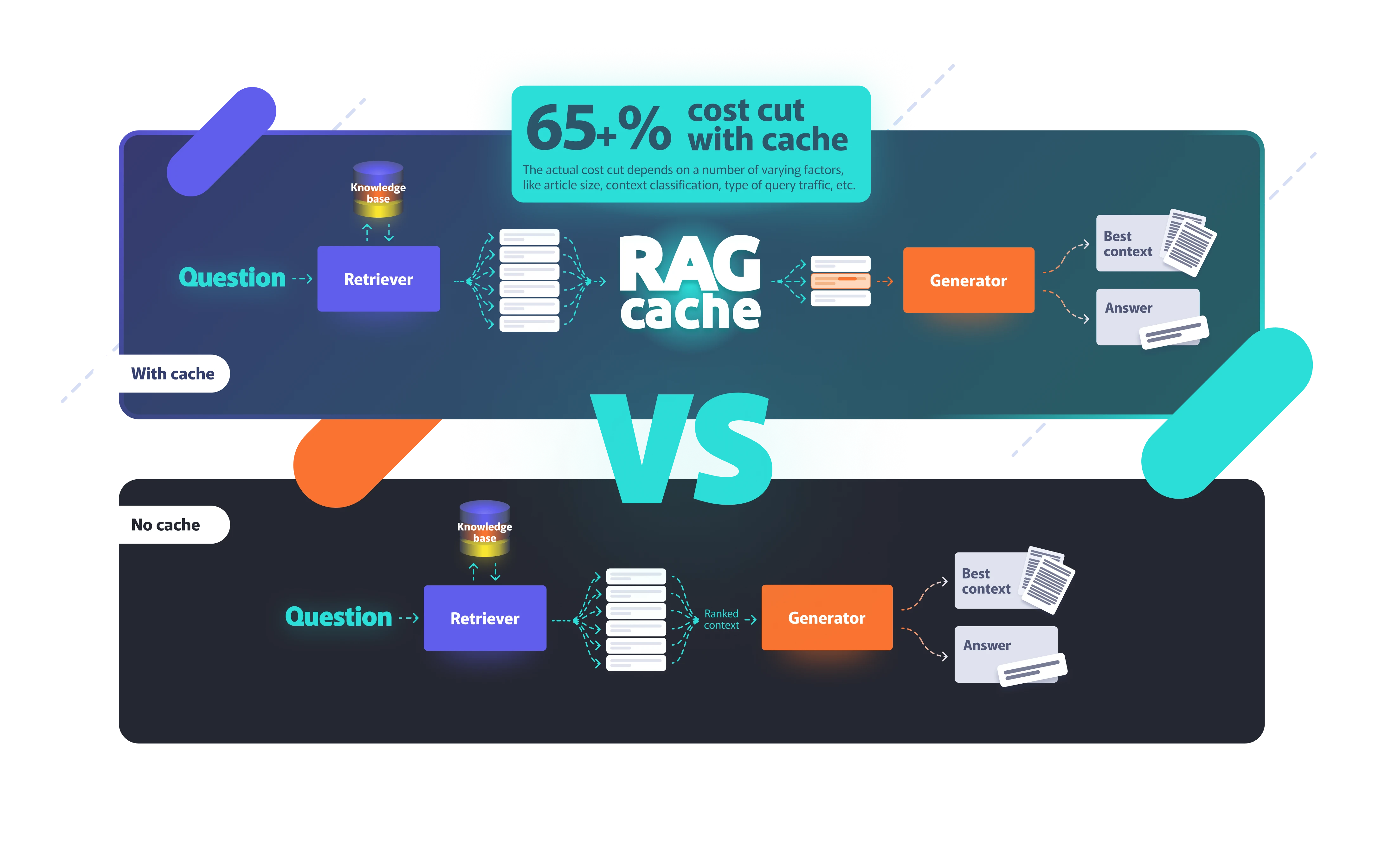
RAG-Buddy, developed by helvia.ai provides a smart patent pending cache that reduces the LLM context size, leading to higher answer quality and considerable cost savings for RAG architectures. With swift plug-and-play implementation, you can enjoy performance and cost benefits straight away without affecting your pipeline!
- For text classification, benefit from up to 65% cost savings with a <1% quality drop.
- For other use cases like RAG+Citation or Q&A, enjoy cost savings of up to 50%.
RAG-Buddy product page.
Start benefiting today

Reduce costs
RAGCache decreases the context size, reducing the number of query tokens. Fewer tokens mean lower costs for either a hosted LLM or your own LLM.

Improve Answer Quality
Smaller context size improves answer quality. This is laid out in the paper "Lost in the Middle" ([2307.03172] Lost in the Middle: How Language Models Use Long Contexts).

Get faster response times
LLMs are faster with a smaller context because of reduced token processing time. Another result is the effect known as Attention Mechanism: In transformer architectures, attention is computed between all pairs of tokens. This operation is quadratic in time complexity concerning the number of tokens, which means a longer context could significantly increase latency.

Effortless integrations
RAG-Buddy's RAG cache is designed as a proxy for your existing LLM. Integration is as easy as adding a couple of lines of code to your existing code base.

Why yet another LLM cache
Exact match caches (like Redis or SQLite) work but have few hits. Semantic caches are hard to implement correctly and have a high risk of big mistakes. RAG-Buddy's cache addresses both problems with a unique and state-of-the-art solution.
Backed by Science
Helvia.ai RAG-Buddy was developed by scientists with a track record of many years in the NLP and ML space. The algorithm was developed in cooperation with the University of Athens.
Go to helvia.ai labsRAG cache is part of helvia.ai's RAG-Buddy, the ultimate game-changer toolbox for taking your RAG pipeline to the next level.

We use our own products to ensure their effectiveness. By implementing RAG cache for our internal RAG pipelines, we have considerably decreased costs and improved response quality.
Dimi Balaouras, CTO, helvia.ai